Personal AI Architecture
A custom-built skills and automation system that extends Claude with persistent memory, domain expertise, and live workflow automation — purpose-built for how I actually work.
The Core Idea
Out of the box, AI assistants are generic. This system makes Claude permanently aware of my context, decisions, preferences, and domain-specific rules — so I never re-explain myself.
- Skills fire automatically based on what I ask — no manual loading
- Context is never lost between sessions
- Decisions made once are respected forever
- Output format is consistent and shareable without post-processing
- Claude acts as a chief of staff — it anticipates, not just responds
Skills System
Each skill is a structured markdown file that loads into Claude's context when relevant. The examples below are a sample — skills are added as new domains and projects require them.
Each skill has a description block that acts as a trigger. Claude reads what I ask, matches it to skill descriptions, and loads the right one — automatically, before responding.
Decisions already made. Infrastructure details. Rules and prohibitions. Output standards. Workflow patterns. The goal: Claude never needs to ask about something I've already figured out.
Workflow: AI Writing Assistant
6–9 independent Claude agents collaborate to write, critique, and iteratively revise through up to two editorial rounds — each agent operating with zero knowledge of the others.
This workflow doesn't use one AI — it uses a chain of independent agents, each with blank context, simulating a real editorial team: writer, reader, critic, reviser.
Workflow Canvas
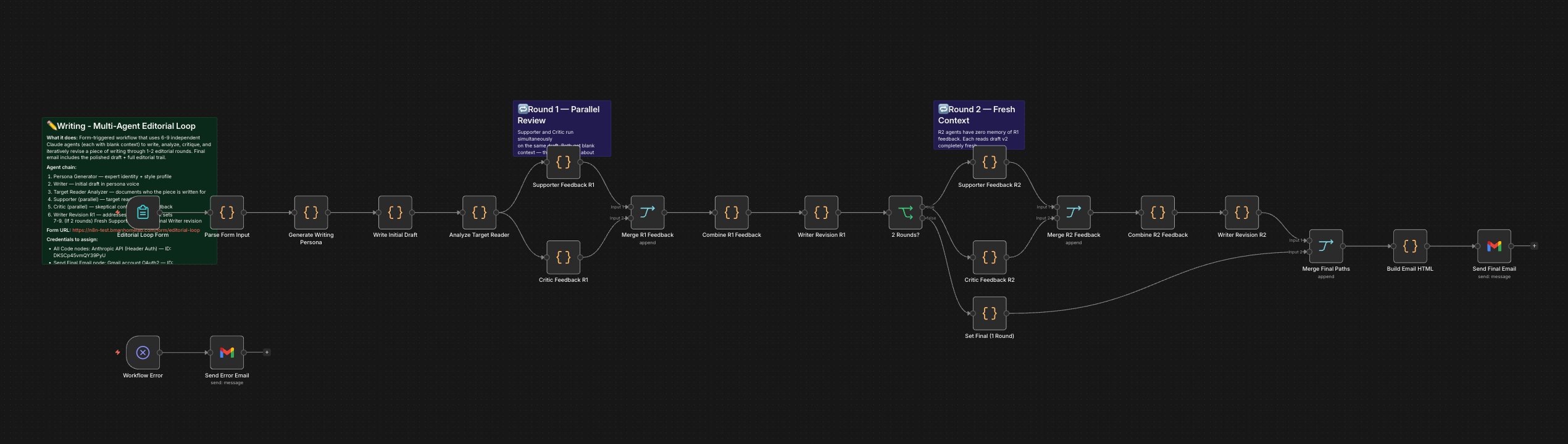
- Why blank context per agent? A single AI in a long conversation becomes a sycophant — it yes-and's its own prior output. Blank context forces each agent to encounter the work cold.
- Why parallel Supporter + Critic? Prevents each from anchoring on the other's perspective. Two truly independent reads.
- Why up to two rounds? Diminishing returns. Round 1 catches structural issues. Round 2 catches what survived.
- Failure mode designed against: Context contamination — AI agents converging on agreement the longer they interact.
The Agent Chain
Workflow: Smart Research with Auto Depth
Natural language query routed through AI depth classification, searched at the appropriate depth, synthesized into a structured brief delivered by email.
The system decides how deeply to search based on what you asked — not a manual toggle.
Workflow Canvas
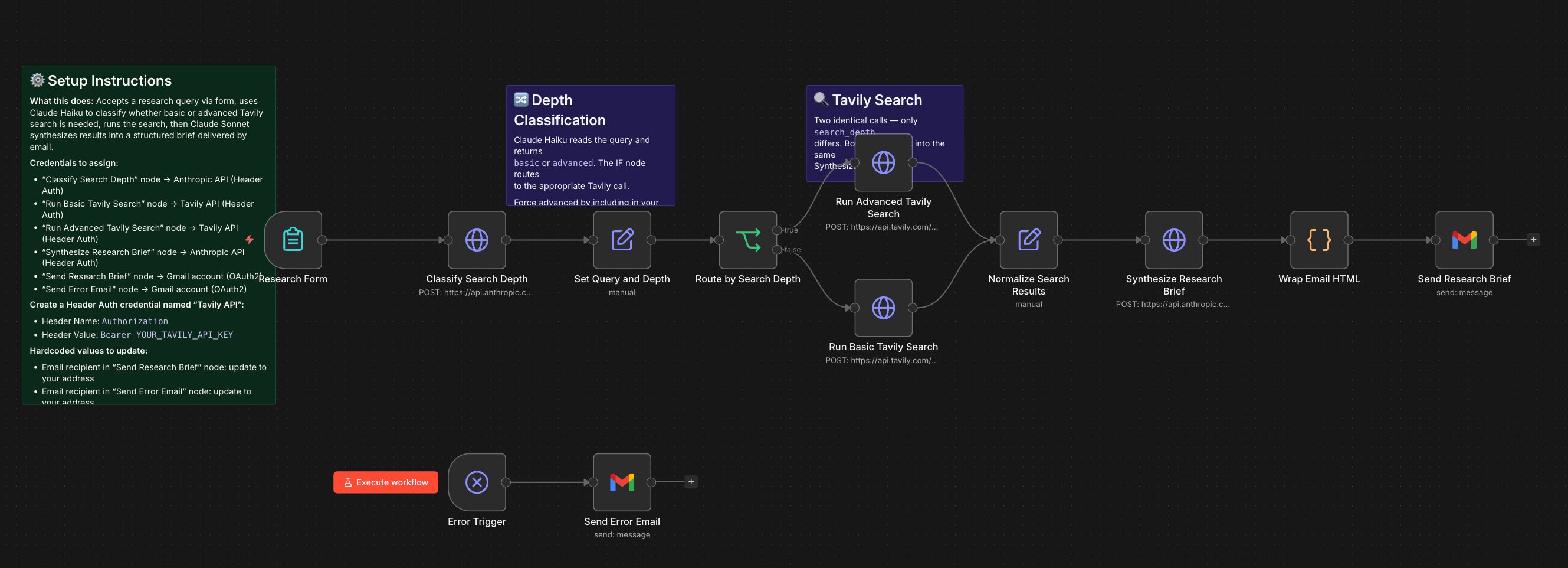
- Why Claude Haiku for classification? Classification is low-complexity — return one word. Haiku is 5-10x cheaper and faster than Sonnet. Haiku handles triage; Sonnet handles thinking.
- Why two Tavily search modes? Deep search costs more and takes longer. The classifier ensures it only fires when the query warrants it.
- Why normalize before synthesis? The synthesis node doesn't need to handle two different data shapes. Cleaner architecture, fewer failure points.
- Known architectural boundary: Output is intelligence for review, not compliance-grade sourcing. The Quality Gate provides the verification layer for higher-confidence use cases.
How It Works
- 1
Research form submission
Plain-English query via web form. The AI decides search depth regardless of phrasing.
- 2
Claude Haiku classifies depth
Returns
basicoradvanced. Fast, cheap, accurate. - 3
IF node routes the search
Basic goes to Tavily standard search. Advanced goes to Tavily deep search, pulling full article content.
- 4
Results normalized
Consistent structure before synthesis regardless of which branch ran.
- 5
Claude Sonnet synthesizes the brief
Executive summary, key findings, source breakdown, actionable takeaways. Max 8,000 tokens.
- 6
HTML brief delivered by email
Clean HTML, opens beautifully on any device.
Workflow: Achievement Log
A real-time capture system for professional contributions — built on the premise that performance reviews reward people who document well, not just people who perform well.
In most organizations, contribution visibility is a function of recency bias — what you did last month matters more than what you did in February. Strong performers who don't document undersell their value at the moment it counts most.
- Why three entry points? Friction is the enemy of capture rate. Three entry points means the right tool is always within reach.
- Why a flat file via SSH, not a database? Portability and zero dependency. Opens in any app, survives any migration, readable directly by AI.
- Why no AI in the capture step? Deliberate. Zero-latency, zero-failure-risk. AI is reserved for synthesis at review time.
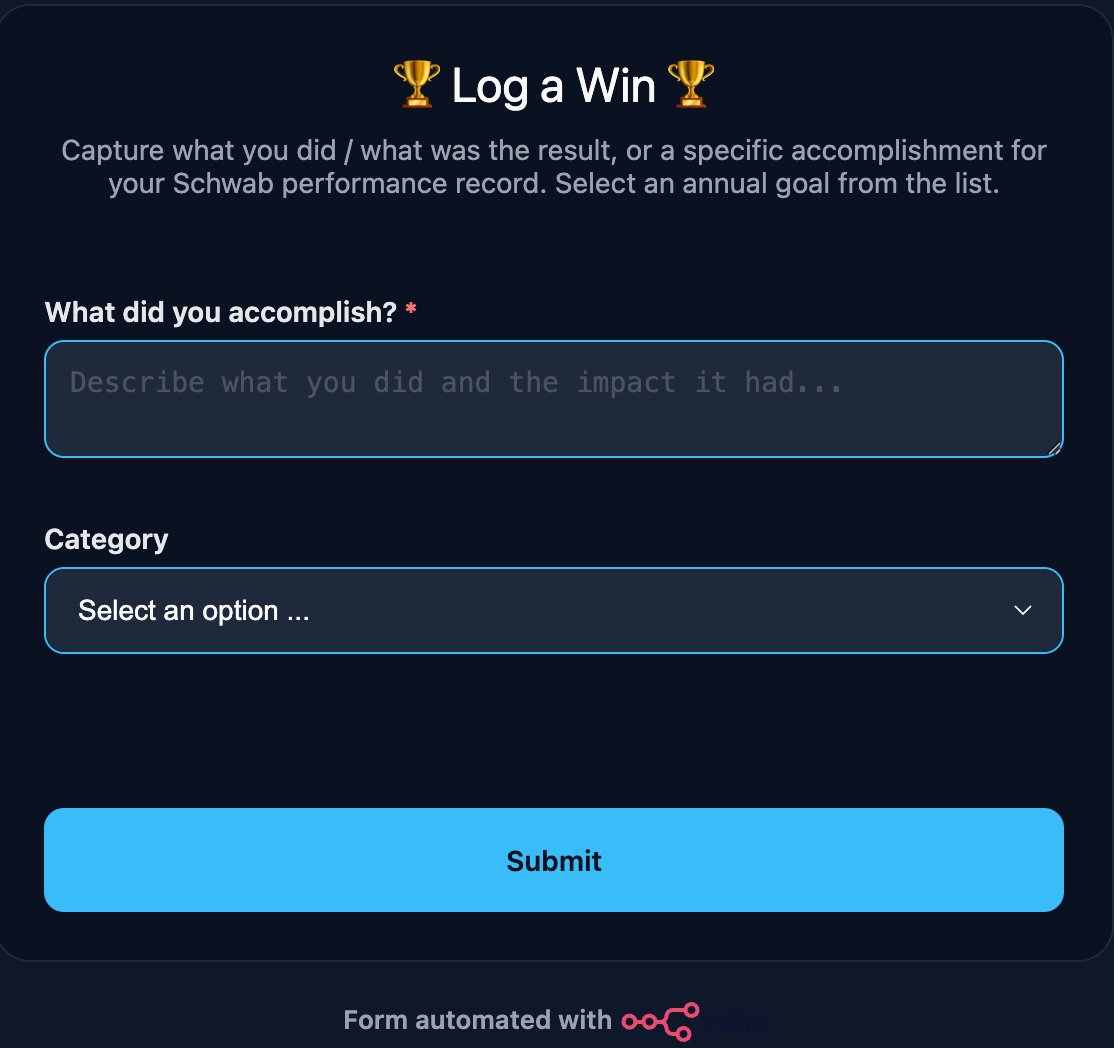
Three Ways to Log a Win
Styled dark-theme form. Dropdown category, free-text entry. Submits and confirms in-browser.
Send any email with [WIN] in the subject. n8n polls Gmail every minute and auto-ingests it.
One-tap iPhone shortcut pings a webhook with a voice-to-text note. Captures the thought in under 10 seconds from anywhere — no app to open, no form to fill, no friction between the moment and the record.
How It Works
- 1
Trigger fires
One of three entry points activates: form submission, Gmail poll detects [WIN] email, or iPhone shortcut webhook fires.
- 2
Data normalized
JavaScript node extracts accomplishment text, category, and timestamps into a consistent format.
- 3
Formatted entry created
Output:
[04/19/2026, 05:39] [Category] [📱 Shortcut] Accomplishment text here - 4
Appended to personal notes vault via SSH
n8n SSHs into the Mac Mini and appends the entry to a structured notes file, timestamped and categorized automatically.
- 5
A living record, ready when you need it
The populated file becomes the primary artifact for the annual review process — a comprehensive, timestamped record ensuring nothing is forgotten or undersold when it counts.
Workflow: AI Output Quality Gate
The verification layer in a three-part professional system. Accepts any AI-generated text and returns a structured confidence report scored across six quality dimensions.
Most AI systems generate output. This one evaluates it. A second Claude instance scores output against a rigorous rubric before it reaches a decision-maker.
Workflow Canvas
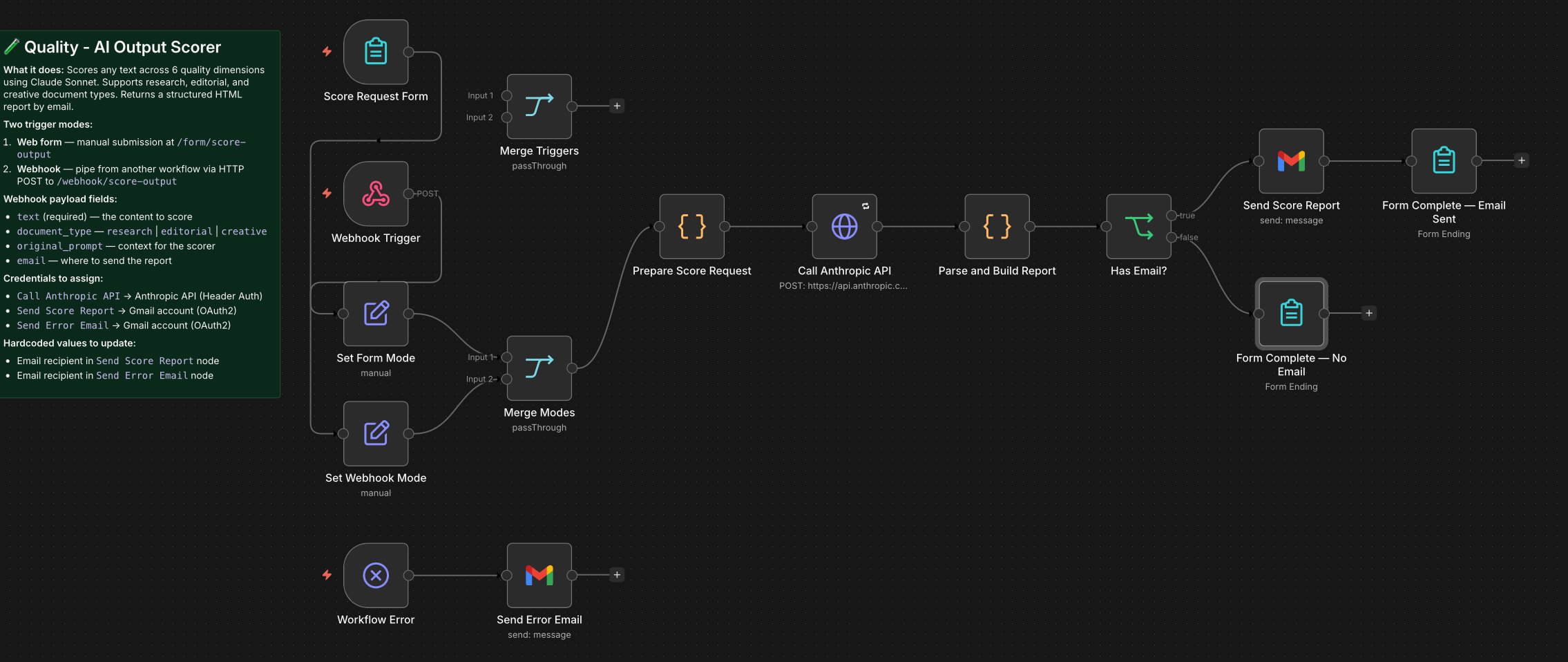
- Why LLM-as-judge? The scorer uses an explicit rubric, different task framing, and no access to the generation context — it encounters the output as a fresh evaluator.
- Why document-type-aware profiles? Source Fidelity matters deeply for research; it's irrelevant for fiction. Three profiles apply appropriate dimension weights.
- Why weighted dimensions? For financial services, Source Fidelity and Analytical Neutrality should outweigh Interpretability.
- Why two entry points? Manual covers ad-hoc use. Webhook enables automated pipelines.
- Known limitation: Cannot independently verify factual claims against external ground truth. Human review remains the final control for high-stakes decisions.
The Six Scoring Dimensions
- Source Fidelity (25% weight in research) — Are claims traceable to cited sources?
- Query Alignment (20% weight) — Does the output directly answer what was asked?
- Claim Specificity (20% weight) — Are assertions specific and falsifiable, or vague and generic?
- Analytical Neutrality (15% weight) — Is the tone objective? Flags directional language and hidden assumptions.
- Confidence Transparency (15% weight) — Does the output distinguish known vs. inferred vs. uncertain?
- Interpretability (5% weight) — Can a reader act on this without ambiguity?
Paste any text, select document type, add context, enter email. Receive a scored HTML report with dimension breakdown, key findings, flagged passages, and recommended action.
Any other n8n workflow can POST output directly via webhook. The Research workflow pipes its brief here automatically before delivery.
System: Morning Intelligence Brief
Five specialized sub-workflows coordinated by an orchestrator — runs every weekday at 6:00 AM. Outputs are merged, synthesized by Claude, and delivered as a structured brief before the trading day begins.
The most complex system in the stack — five workflows running independently and in parallel, in daily production since early 2026.
Orchestrator Canvas
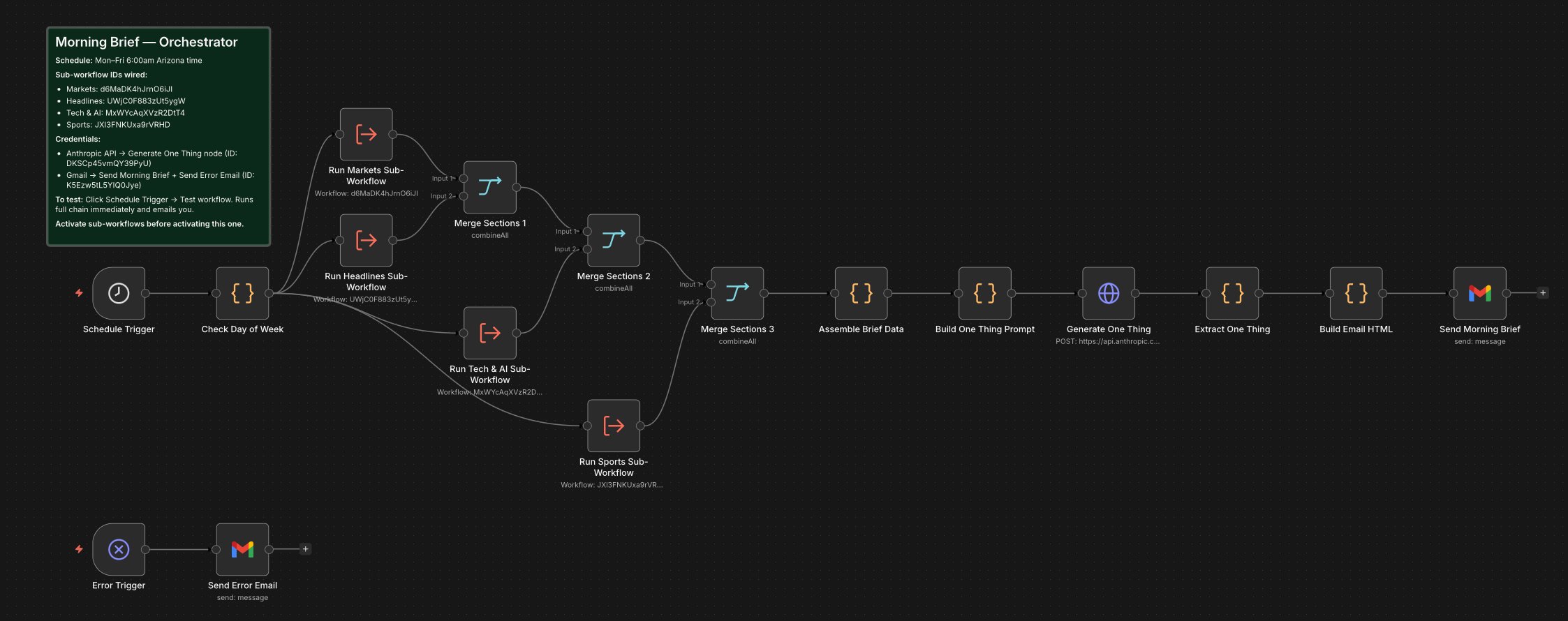
- Why five parallel sub-workflows? Each domain has different data sources, API patterns, and failure modes. A single source failing doesn't take down the whole brief.
- Why an orchestrator pattern? Linear workflows are sequential. The orchestrator fires all five simultaneously — roughly 90 seconds vs. 5 minutes sequentially.
- Why the "One Thing" synthesis step? More information is not always the goal — actionable signal is. Claude Sonnet distills one sentence: the single most important insight before market open.
- Why Check Day of Week? The brief only runs Monday through Friday. No market summary needed on weekends.
- Data source coverage is actively expanding — the architecture accommodates new sources without structural changes to the orchestrator.
The Five Sub-Workflows
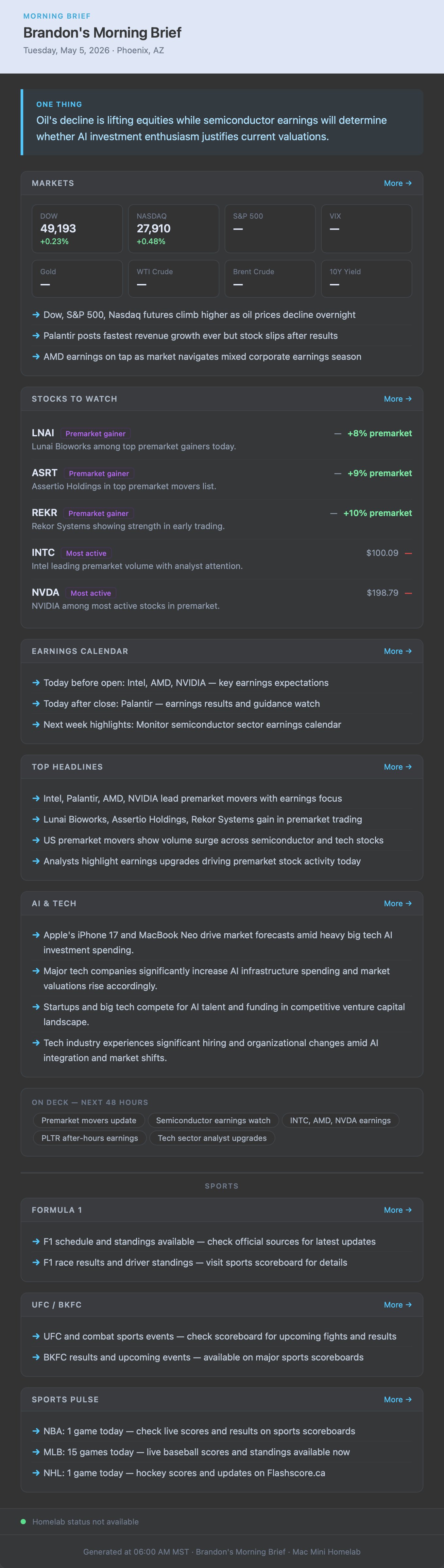
Sample Output
The brief lands in the inbox at 6:00 AM every weekday. The ONE THING section leads every issue.
Workflow: Script Breakdown
Upload a PDF document plus context. Claude Sonnet analyzes it and emails back four formatted sections: scene analysis, annotated rehearsal script, clean script, and camera-ready styling direction.
Upload a PDF, provide any relevant context, and receive a structured professional-grade breakdown in minutes.
Workflow Canvas
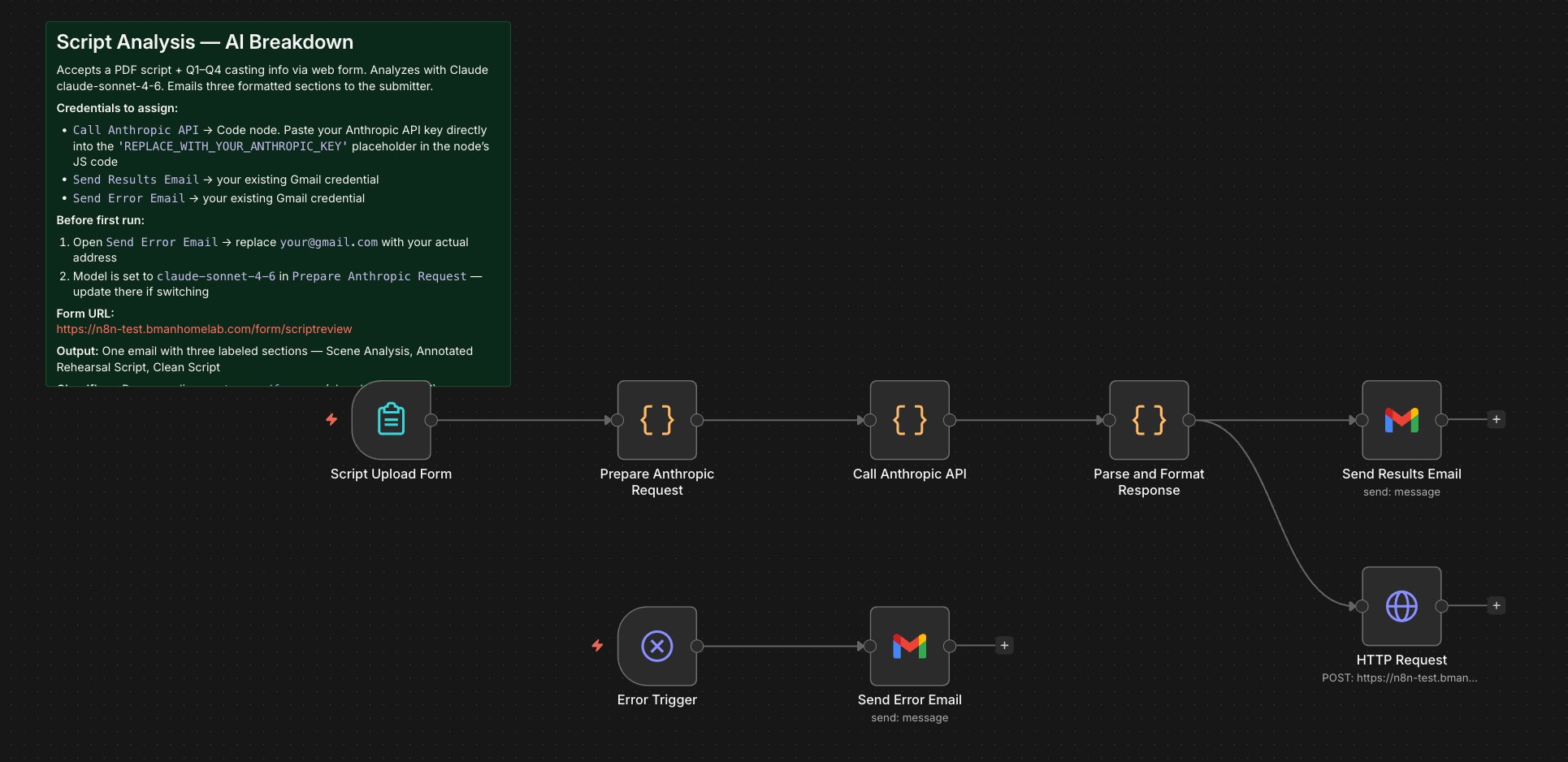
- Why native PDF to Claude? Text extraction mangles formatting — stage directions, character names, scene headers lost or flattened. Claude's native document understanding preserves what matters.
- Why single-pass four-section output? One context window — all four outputs internally consistent. Four separate calls risk contradictions and cost roughly 4x more in API tokens.
- Why the PDF binary handling matters: n8n's filesystem mode requires
getBinaryDataBuffer()— not the standard binary field. Getting this wrong produces a silent failure where Claude receives an empty document.
- Scene Analysis — objectives, subtext, power dynamics, beat-by-beat coaching notes
- Annotated Rehearsal Script — full script with inline director-style coaching
- Clean Script — unadorned, ready for memorization or scene partner use
- Audition Appearance & Styling — camera-calibrated direction on clothing, color palette, hair, makeup, and accessories
Why This Matters for AI Strategy
What looks like personal productivity tooling is actually a working model of enterprise-grade AI integration patterns.
- Shared context primitives — DRY principle applied to AI system design. One source of truth, referenced everywhere.
- Skill-based modularity — Discrete, trigger-aware modules. Adding a new domain = adding a new skill file.
- AI as classifier and middleware — Right model, right job. Haiku classifies; Sonnet synthesizes.
- Multi-agent orchestration — Independent blank-context agents, parallel execution, conditional routing, feedback merging.
- LLM-as-judge evaluation — AI output scored by a second AI before reaching a decision-maker.
- Multi-workflow orchestration at scale — Five independent workflows coordinated in parallel. Pipeline architecture, not automation scripting.
- Human-in-the-loop design — Automate what's safe; confirm what matters.
- Error handling and observability — Every external API call retries twice before alerting. Production ops discipline.
What's Next
The system is in active use — what follows is how it evolves.
n8n runs on a Mac Mini M1 in Docker via OrbStack. Zero dependency on third-party cloud automation services — full control, full observability, no subscription lock-in.
Every pattern here — orchestration, evaluation, modular skills, self-improvement — maps directly to how enterprise AI systems are designed and operated at scale. This is the same thinking, applied personally first.